トラブル解決系のネタが続きますが、自分のメモ用として残した結果、誰かの役に立てたら良いなの精神で記録を残しておきます。
現象の概要
サイト全体をshift-jisからutf-8に文字コードを変更し、グローバルメニュー部分をPHPでインクルードした際に謎の空白部分が出現。デザインが崩れてしまう。また、該当の空白部分を削除しようとしてソースを触ってみるが、どこにも空白部分は見当たらない。
解決方法
消し方は非常に簡単で、Terapad等の文字/改行コード指定保存ができるメモ帳で、文字コードをUTF-8からUTF-8Nに変更するだけです。
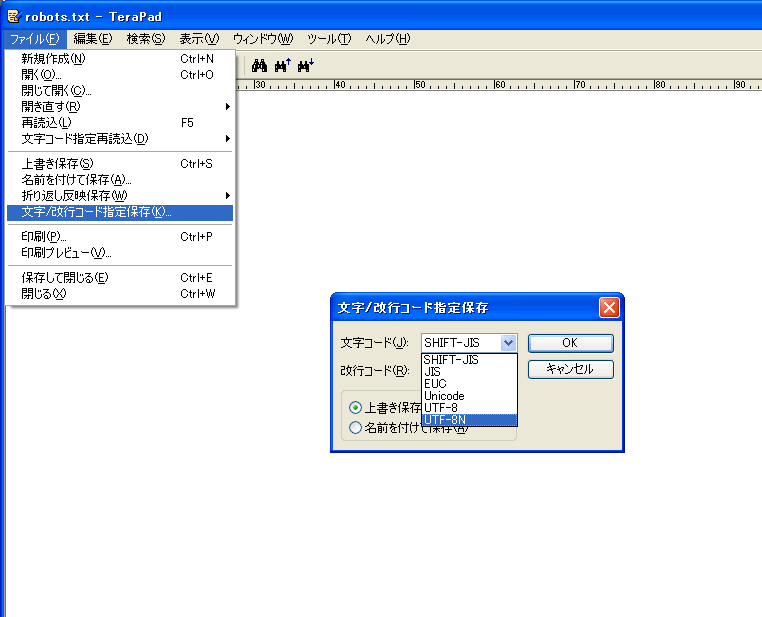
これはTerapadの例です。shift-jisからutf-8に変換するときも、utf-8Nを選んでおいたほうが無難です。
もう少し現象の詳細を説明していきます。まず、謎の空白について画像で説明してみます。
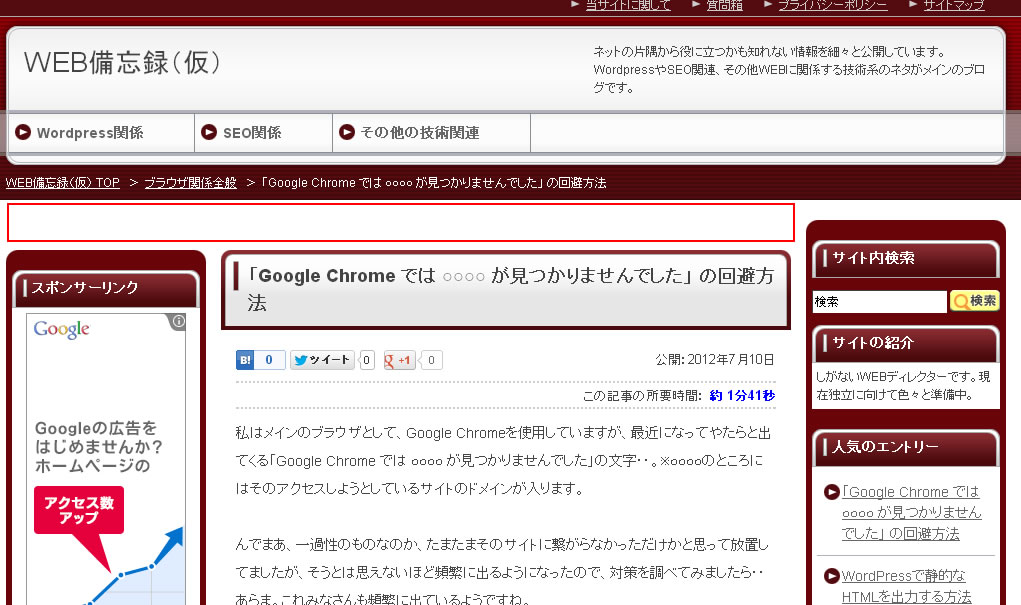
わざわざ画像で再現してみましたが、PHPのスクリプトをインクルードした場合や、HTMLをUTF-8で保存した際に、画像の赤枠で囲った部分の様に、謎の空白行が出てしまい、デザインが崩れてしまう場合があります。
ソースの中をのぞいてみると、こんな感じで「”(ダブルクォーテーション)」が表示されており、何も無い行が勝手に追加されている状態となっています。
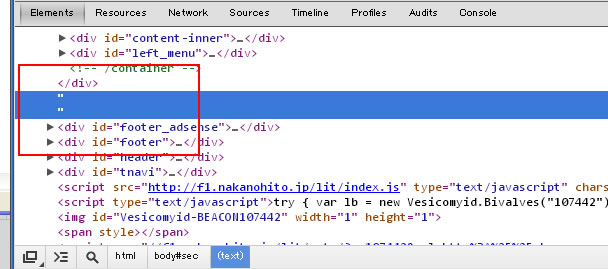
赤枠で囲った部分に謎のダブルクォーテーションが出現しています。
<HTML>タグの開始タグよりもさらに前(すなわち最前列)に出現する場合もあります。
まず、なぜこのような現象が起こるのかというと、「BOM」付きのUTF-8で保存してしまったためです。UTF-8には2種類あり、世間一般的に認知されているのが「UTF-8」であり、もう一つ、「UTF-8N」という、BOM無しの文字コードも存在しています。
BOM【Byte Order Mark】とは?
UnicodeのUTF-16など16ビット幅のエンコーディング方式において、エンディアンを指定するためにファイルの先頭に記入される16ビットの値。
UTF-16などではビット列の並びとしてビッグエンディアンとリトルエンディアンの両方を許容しているため、誤ったエンディアンで文書を読み込むと判読できなくなってしまう。このため、ファイルの先頭のBOMを読んで、文書がどちらのエンディアンで作成されたかを判別してから本文を読み込む。
BOMは16進数で「FEFF」という16ビットの値で、誤ったエンディアンで読み込むと、これが「FFFE」となる。BOMが「FFFE」となった場合には逆のエンディアンを使って読み込めば正しく読み込むことができる。
BOMはエンディアンの判別だけでなく、文書がUnicodeで記述されているかどうかを判別するために用いられることもある。このため、エンディアンが関係ないUTF-8などの文書でも先頭にBOMがついている場合がある。
Unicodeとほぼ等価であるISO 10646では、BOMに相当するコードは「ZERO WIDTH NON-BREAKING SPACE」と呼ばれ、ビット列はBOMと同じく16進で「FEFF」だが、文書の途中に登場してもいいことになっている。
上記は引用文ですが、さらに文中に出てくるエンディアンって何?とさらに疑問が沸いて来ますが、私もそこまでよくわかっていないのでさらっと流します(w。一般的には「2バイト以上のデータ量を持つ数値データを記録したり転送するときには1バイトごとに分割するが、その際の記録/転送を行なう順番のこと。」と言われていますが、文章の先頭に勝手に付加されてしまう情報のようなものと捉えておいてください。
このBOMによる謎の空白ですが、PHPのインクルード処理の場合によく発生してしまいます。その場合、十中八九、原因は文字コードをUTF-8で保存しているために起こってしまうのです。
同様に謎の空白部分が出てしまった方は、まずはBOMによる空白行を疑い、メモ帳等でUTF-8Nで保存しなおしてみてください。だいたいはこの方法で空白行が改善されるはずです。
インクルードさせるPHP側だけでなく、読み込ませる側のファイル(HTMLやPHPファイル等)の文字コードがUTF-8Nになっていない場合もありますので、併せて確認してみると良いですね。